# AWS Athena에 테이블이 생성이 되어있다.
- 컬렴명은 아래와 같다.
기존 테이블 컬럼 : invoiceno, stockcode, description, quantity, invoicedate, unitprice, customerid, country
- 총 8개의 컬럼으로 구성되어진 테이블이 있다. 여기서 Movie-Dataset-Latest.csv라는 파일을 S3버킷에 업로드 후 해당 파일의 컬럼을 기존에 구성된 테이블 뒤에 id, title, release_date 이렇게 3개의 컬럼을 생성하고 데이터를 붙여보자.
변경 테이블 컬럼 : invoiceno, stockcode, description, quantity, invoicedate, unitprice, customerid, country, id, title,release_date (빨갛게 표시된 컬럼은 다른 파일에서 불러온 데이터를 부어넣을 것이다.)
- 작업을 시작해보자.
1. S3에 추가로 CSV 파일을 업로드 하자.
- 기존에는 S3에 하나의 파일만 업로드 되어 있었고, 해당 파일의 컬럼을 기준으로 아테나에서 테이블을 생성 하였다.
- 추가로 하나의 파일을 더 업로드 하자.
- 기존 CSV 파일 하나만 업로드 되어있는 상태
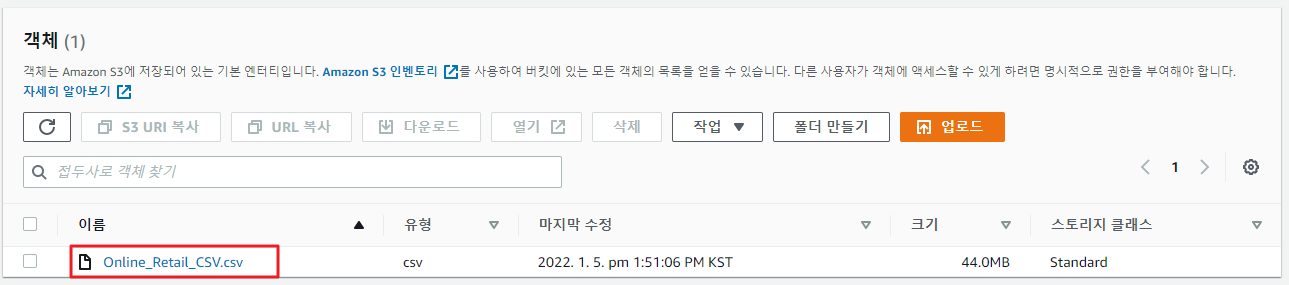
- 추가로 CSV 파일을 업로드한 상태 2개의 CSV 파일이 업로드 되어있다.
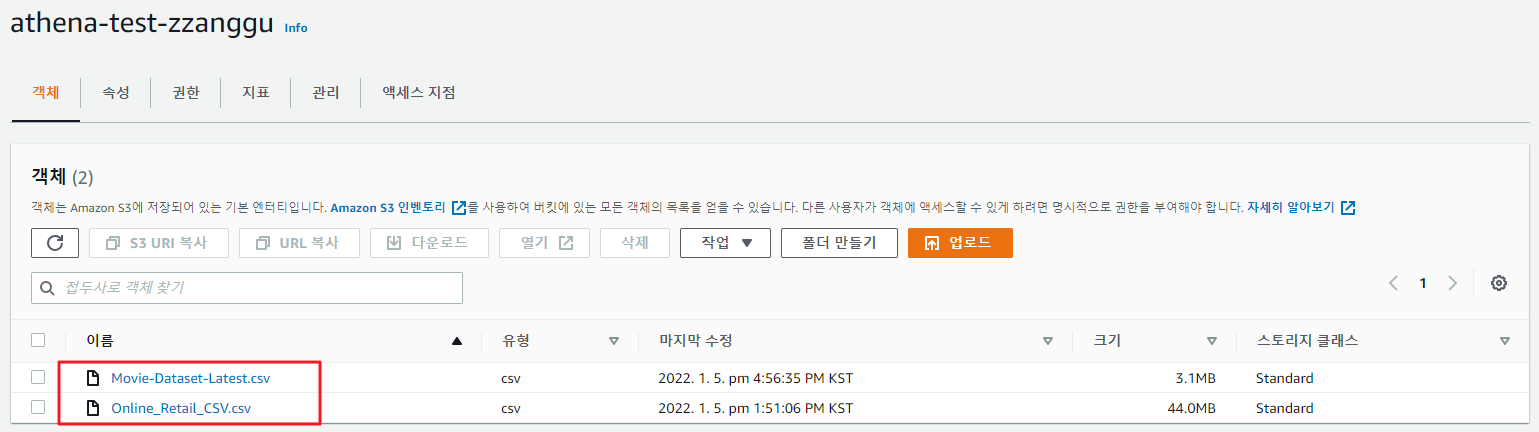
2. AWS Athena에서 테이블을 수정하자 (3개의 컬럼을 추가로 생성(추가한 파일의 컬럼))
- 현재 Athena의 컬럼 리스트 이다. 여기서 country 옆에 3개의 컬럽을 추가하고, 추가한 파일의 3개의 컬럼 데이터를 로드해보자.

- AWS Athena에서 분명히 컬럼을 추가하는 SQL 문이 있겠지만... 추후에 알아보기로 하고 여기서는 작업을 조금 간편화 하기위해 테이블을 삭제 후 새로 생성을 해보자.
- 아래의 쿼리문을 사용해서 테이블을 생성하자.
CREATE EXTERNAL TABLE IF NOT EXISTS zzanggudb.zzanggudb01 (
`InvoiceNo` int,
`StockCode` string,
`Description` string,
`Quantity` int,
`InvoiceDate` date,
`UnitPrice` float,
`CustomerID` int,
`Country` string,
`id` string,
`title` string,
`release_date` date
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://athena-test-zzanggu/'
TBLPROPERTIES ('has_encrypted_data'='false');- 쿼리가 성공적으로 실행 되었고, 테이블이 신규로 생성 되었다.
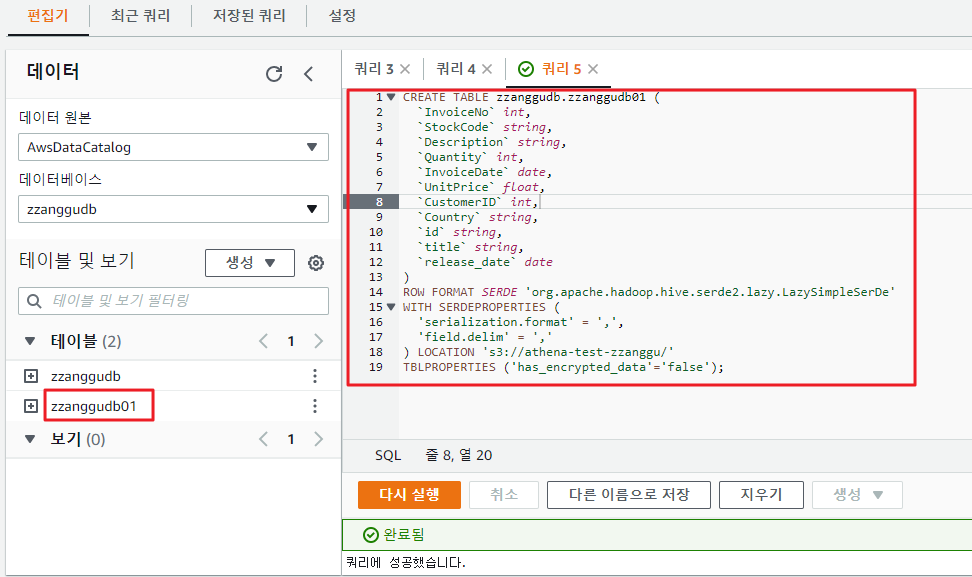
2. 새로운 테이블을 생성하고 데이터를 조회해 보자.
- 테이블을 신규로 생성하고, S3 저장소 위치도 정상적으로 설정 하였지만 데이터를 정상적으로 로드하지 못하였다.
- 문제점이 무엇일까... 이전 테이블 생성과 다른점은 테이블을 생성할때 GUI 환경에서 생성한것이 아닌 쿼리로 테이블과 컬럼을 생성한것이 다른점인데...ㅠㅠ 데이터 베이스를 신규로 생성하고 테이블을 다시 생성해보자...

- AWS 아테나에서 신규 데이터베이스와 테이블 생성하기
//데이터 베이스 생성
CREATE DATABASE zzanggudb01//테이블 생성
CREATE EXTERNAL TABLE IF NOT EXISTS zzanggudb01.zzanggudb (
`InvoiceNo` int,
`StockCode` string,
`Description` string,
`Quantity` int,
`InvoiceDate` date,
`UnitPrice` float,
`CustomerID` int,
`Country` string,
`id` string,
`title` string,
`release_date` date
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://athena-test-zzanggu/'
TBLPROPERTIES ('has_encrypted_data'='false');- 데이터 확인하기
SELECT id, title FROM "zzanggudb01"."zzanggudb" limit 10;- 위의 쿼리를 실행하여 데이터를 확인결과 아래와 같이 데이터가 조회 되었다.
- 데이터가 깨져서 조회가 되는 모습인데... 뭔가 이상하다.
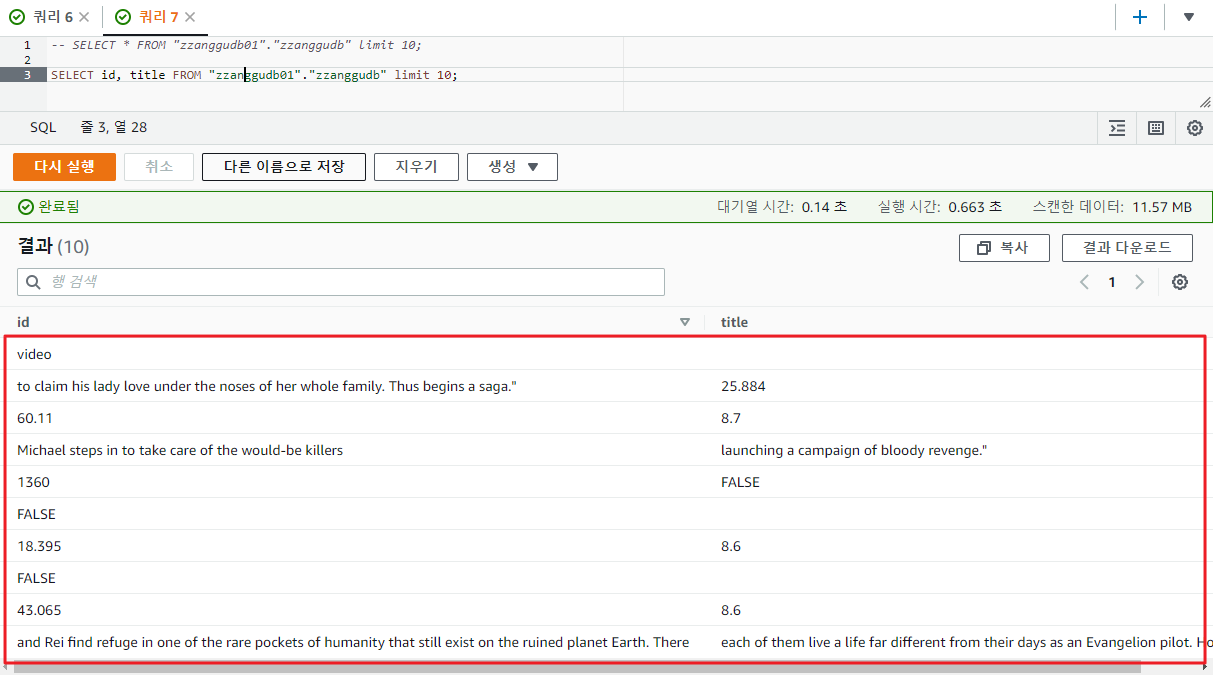
- 확인해보니 Delimiter 값이 중간 중간에 들어가 있어서 깨진거 였다.
3. Delimiter 값에 대한 제한 없는 파일을 생성 후 새로운 테이블을 생성하자.
- Delimiter 값이 없는 CSV 예제파일 생성: 이전의 샘플 파일은 online retail.csv 파일을 재사용 하자.
- 기존의 컬럼값과 데이터 값을 아래와 같이 임의로 변경한다.
- 기존의 online retail.csv의 테이블 리스트 건수는 541,910건이다.
- 신규로 작성한 파일의 이름은 online_retail_CSV_Target.csv 이라는 파일로 생성 하였다.
- 내용은 아래와 같다.
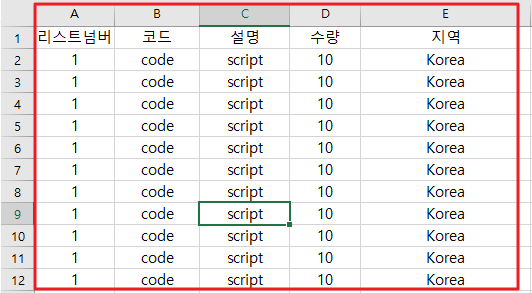
- 결론적은로는 2개의 파일이 있으며 리스트 건수는 두 파일 동일하게 541,910건 이다.
- 신규 테이블을 생성후 컬럼값은 아래와 같을 것이다.
invoiceno, stockcode, description, quantity, invoicedate, unitprice, customerid, country, 리스트넘버, 코드, 설명, 수량, 지역
- 초록색으로 표시된 컬럼은 online retail.csv라는 파일의 데이터를 읽어올 것이고 주황색으로 표시된 컬럼은 online_retail_CSV_Target.csv이라는 파일에서 데이터를 불어올것이다.
- S3에서 테이블을 생성하는 프로세스
- 신규 테이블을 생성전에 online_retail_CSV_Target.csv파일을 S3경로에 업로드 한다.
- 업로드 후 아래와 같이 2개의 파일이 존재할 것이다.

- AWS Ahtena로 이동하여 테이블을 생성한다.
- 테이블 명은 online_retail_target 이다.
CREATE EXTERNAL TABLE IF NOT EXISTS zzanggudb01.online_retail_target (
`InvoiceNo` int,
`StockCode` string,
`Description` string,
`Quantity` int,
`InvoiceDate` date,
`UnitPrice` float,
`CustomerID` int,
`Country` string,
`리스트넘버` int,
`코드` string,
`설명` string,
`수량` int,
`지역` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://athena-test-zzanggu/'
TBLPROPERTIES ('has_encrypted_data'='false');- 생성하고 보니 착오가 있었다. 나는 데이터를 여러개 붙이면 가로로 테이블을 나열하고 결과값을 붙일수 있을거라 생각 했는데 그게 아니었다. 데이터를 추가하면 즉 새로운 CSV 파일을 생성하면 데이터는 행으로 늘어나는것이 아니라 열이 생성한 CSV 파일만큼 증가하였다.
- 생성한 테이블을 COUNT(*) 조회를 해보면 정확히 2배가 늘어난것을 확인할 수있다.
- 즉 컬럼값을 무시하고 데이터는 열 방향으로 증가하는 것이다.
- 그래서 만약 데이터레이크나 데이터 웨어하우스를 AWS S3로 사용할 경우 각각의 테이블단위로 S3 버킷을 생성해야 하고 해당 컬럼에 PK나 FK같은 구분자를 둬서 업데이트 되는 데이터와 기존의 데이터를 구분할 수 있을 것이다.
SELECT COUNT(*) FROM "zzanggudb01"."online_retail_target";
- 그렇다면 주기적으로 업데이트 되는 CSV파일에 S3는 어떤 반응을 보일까...
'⭐ AWS > Athena' 카테고리의 다른 글
| Athena Case Statement (0) | 2023.07.20 |
|---|---|
| ALB Access 로그를 S3에 저장 후 Athena를 통한 분석 (0) | 2022.07.22 |
| Athena와 람다를 활용한 데이터 분석 (0) | 2022.01.18 |
| Athena 쿼리 예약 (0) | 2022.01.18 |
| S3에 저장된 CSV 파일을 Athena로 분석하기 (0) | 2022.01.05 |


