# AWS S3에 저장된 엑셀 파일을 AWS Athena를 기반으로 분석하기
1. 새로운 S3 버킷을 생성하고, CSV로 만들어진 예제 파일을 업로드한다.
- 이 예제 파일은 인터넷에 공개된 오픈 데이터이다.
- 파일명은 onlie retail.xlsx이고, 이 파일을 CSV확장자로 변환하여 사용한다.
- 아래의 URL에서 onlie retail.xlsx 파일을 다운로드할 수 있다.
- 해당 파일을 다운로드 한 뒤 CSV 확장자로 변경하여 저장한다.
https://www.kaggle.com/mrmining/online-retail
online_retail
www.kaggle.com
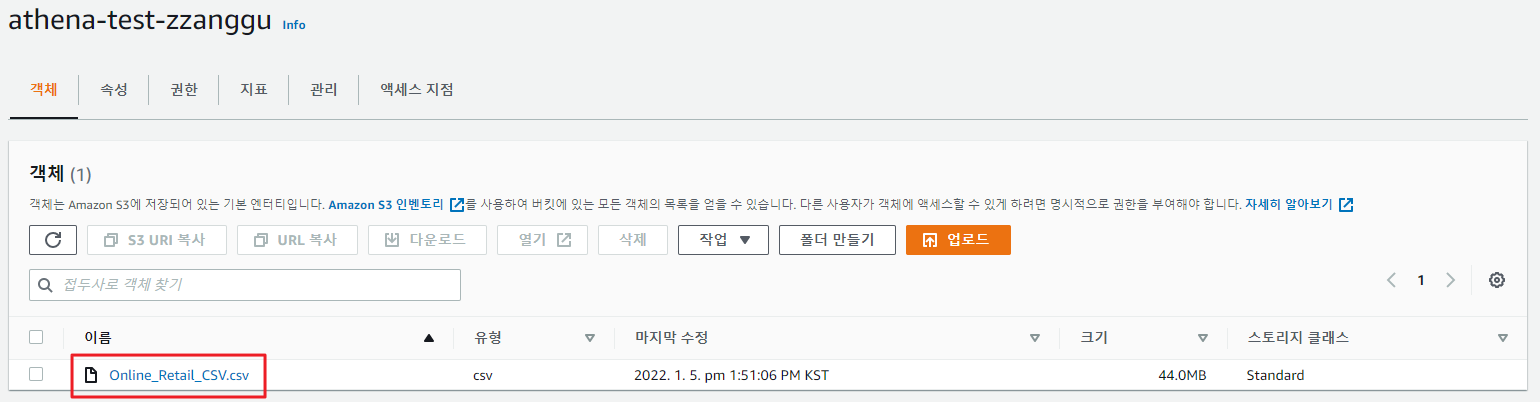
- AWS S3로 이동 후 새로운 버킷을 생성한다.
- 나는 athena-test-zzanggu라는 버킷을 생성하였고, 생성된 버킷에 위의 샘플 파일을 업로드하였다.
- CSV 파일로 변경하면 기존의 엑셀 파일보다 용량이 다소 늘어나는 것을 확인할 수 있다.
2. AWS Athena 서비스에서 해당 S3 버킷의 데이터를 기반으로 테이블 생성하기
- AWS Athena 서비스로 이동한다.
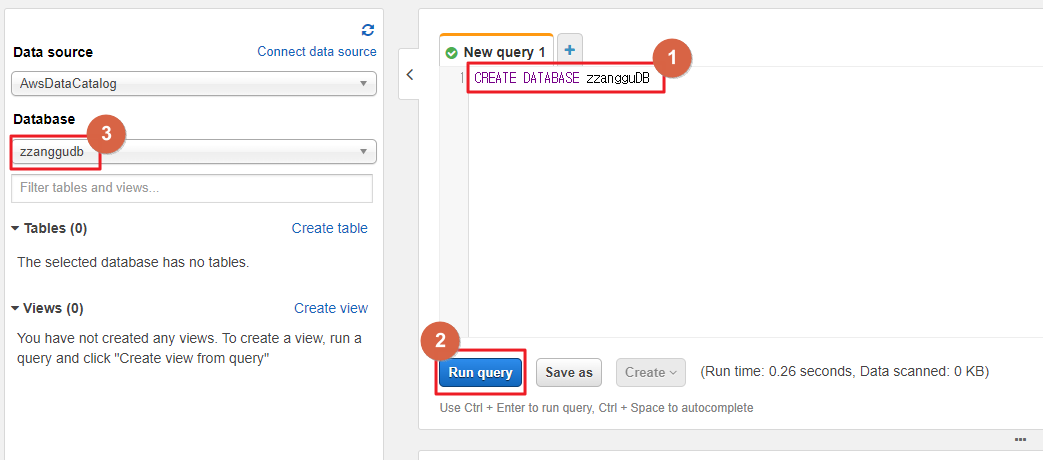
- 새로운 데이터베이스를 생성합니다.
CREATE DATABASE zzangguDB- 쿼리를 실행 후 왼쪽 데이터베이스 탭에서 생성한 데이터베이스를 선택합니다.
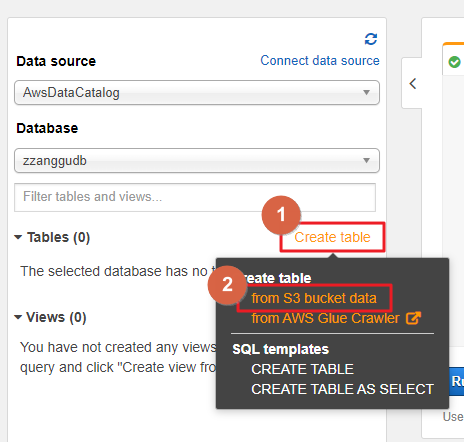
- 생성한 데이터베이스에 S3 버킷 데이터 기반 테이블을 생성합니다.
- S3에 저장된 CSV 파일을 기반으로 테이블을 생성할 것이므로 from S3 bucket data를 선택합니다.
3. Ahtena에서 테이블 생성 상세 → 아래와 같이 데이터 베이스 이름, 테이블 이름 등 입력합니다.
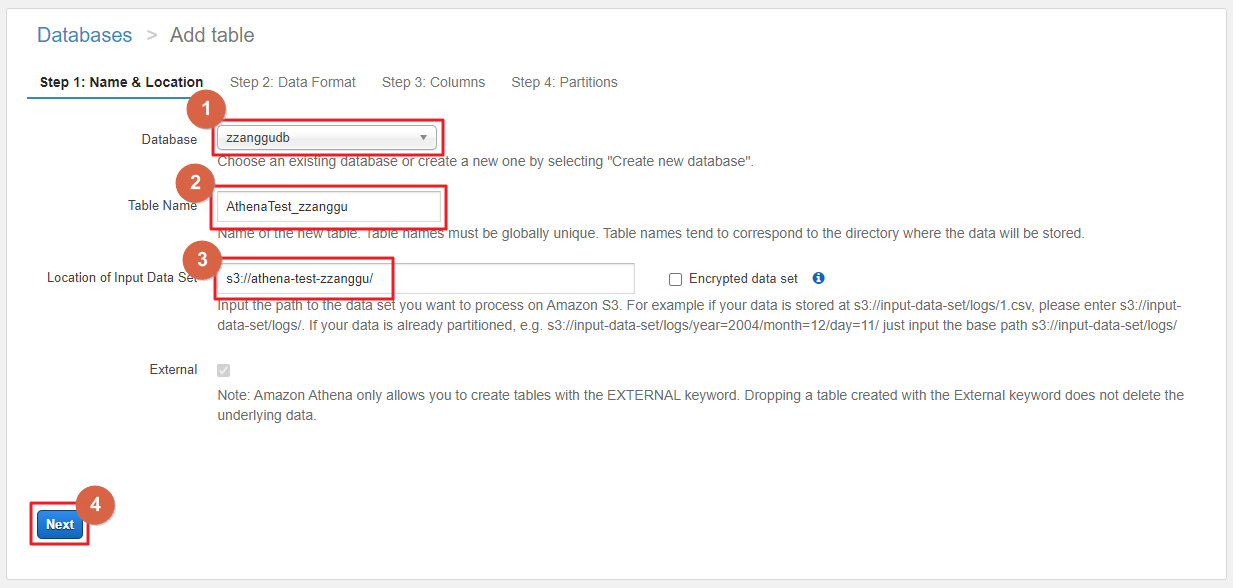
- Step2에서 데이터 포맷을 선택합니다.
- 여기서는 CSV 파일을 샘플데이터로 하기 때문에 CSV를 선택 후 다음으로 넘어갑니다.

- 다음은 칼럼 이름과 칼럼 타입을 지정해주는 단계입니다. (칼럼과 타입을 일일이 손으로 지정해야 하기 때문에 칼럼이 많으면 막일 작업이 될 수 있습니다...-_-;;)
- 일단 해당 예제 CSV 파일의 헤더를 파악해 봅시다.

InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country로 총 8개의 값을 나타 냅니다.
- 여기서 짬을 내어... Number, int, unit의 차이점을 알아보자. "더보기" 클릭.
- 칼럼 값을 아래와 같이 칼럼 이름과 칼럼 타입을 지정 후 다음을 클릭하여 다음 단계로 넘어간다.
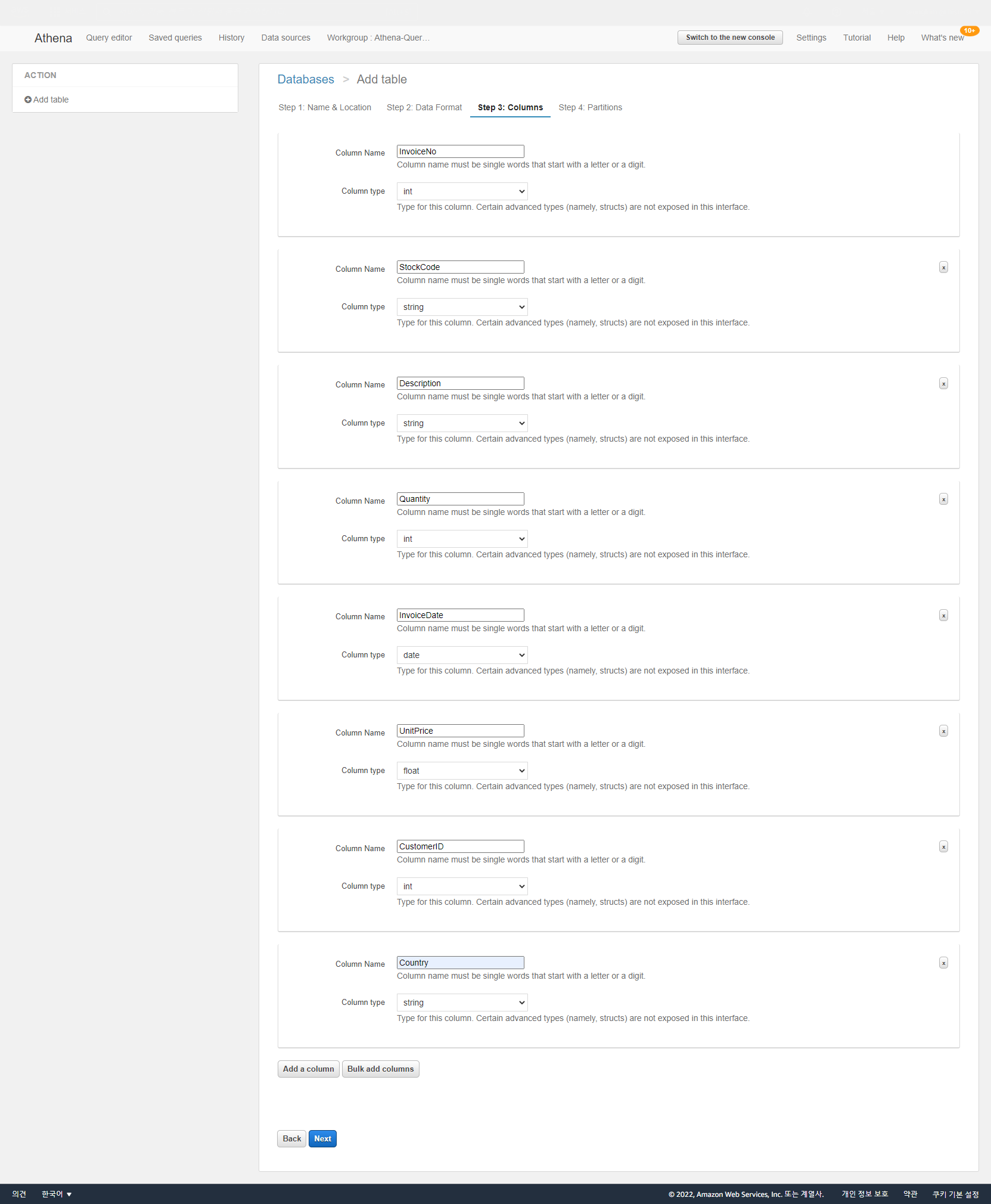
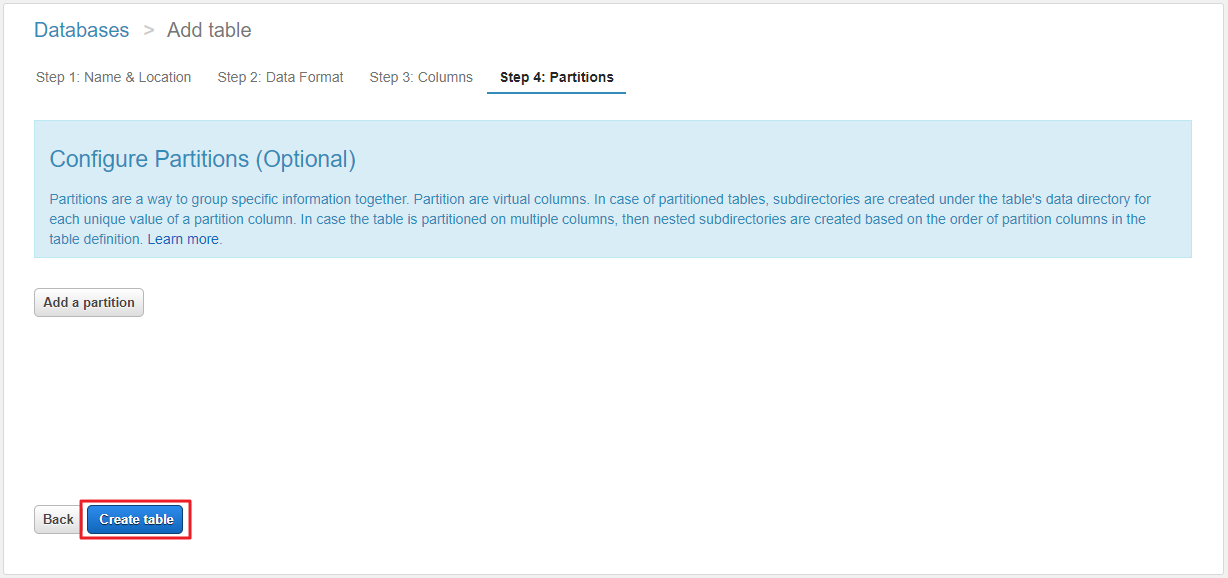
- 테이블 생성 설정 마지막으로 파티션을 설정하는 단계가 나온다. (파티션 설정은 추후에 하기로 하고 여기서는 다음 단계로 넘어가자.)
- 테이블 생성 버튼을 클릭하여 테이블을 생성한다.
- 테이블이 정상적으로 생성되면 아래와 같이 화면에 표시된다.
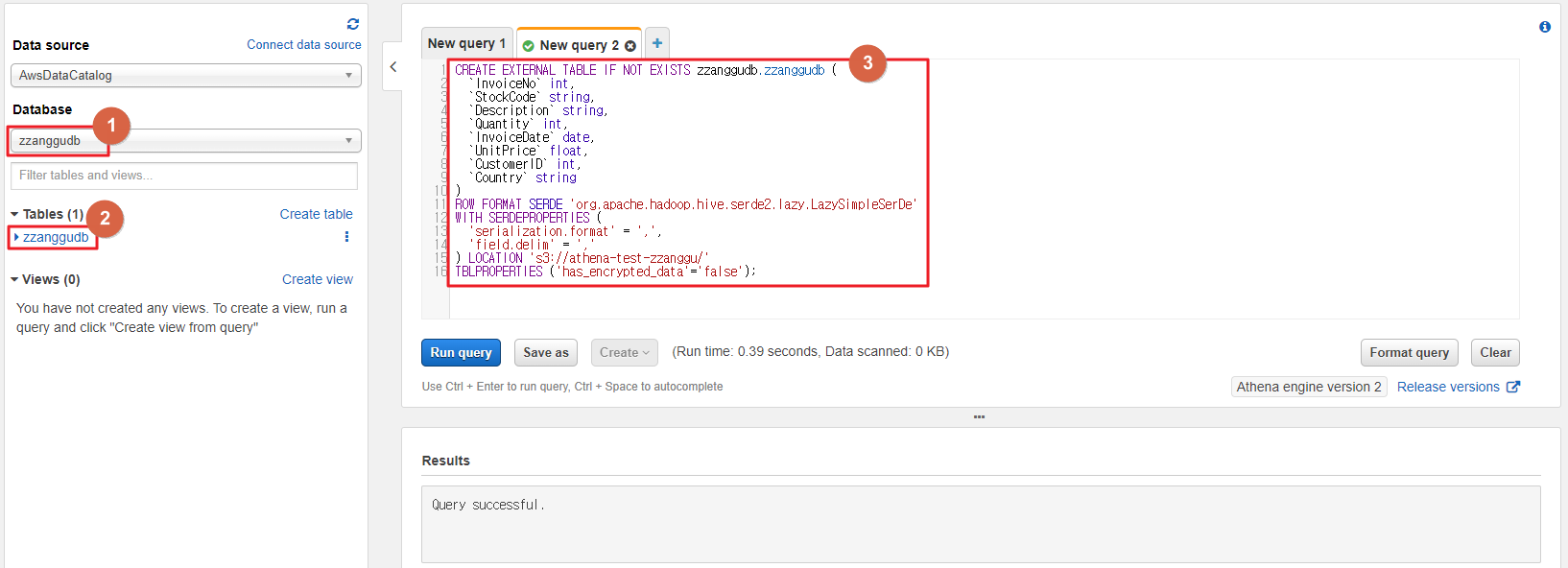
- 테이블 생성한 쿼리문 (테이블을 생성하면 화면에 생성한 쿼리문을 표시해 준다.)
CREATE EXTERNAL TABLE IF NOT EXISTS zzanggudb.zzanggudb (
`InvoiceNo` int,
`StockCode` string,
`Description` string,
`Quantity` int,
`InvoiceDate` date,
`UnitPrice` float,
`CustomerID` int,
`Country` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://athena-test-zzanggu/'
TBLPROPERTIES ('has_encrypted_data'='false');4. 생성한 테이블을 기반으로 데이터 조회하기
- 첫 번째 줄에 칼럼 값이 그대로 INSERT 되어 테이블에 저장된 거 같다. 그래서 데이터가 없는 부분은 타입이 맞지 않기 때문에 표시가 안된 것이다.
- 헤더 타입은 모두 String으로 되어 있을 것이고, 해당 칼럼은 int, date 등 칼럼 타입을 지정하였으므로, String타입의 칼럼 값은 타입이 맞지 않아 정상적으로 INSERT가 되어도 표시가 안된 것이다.
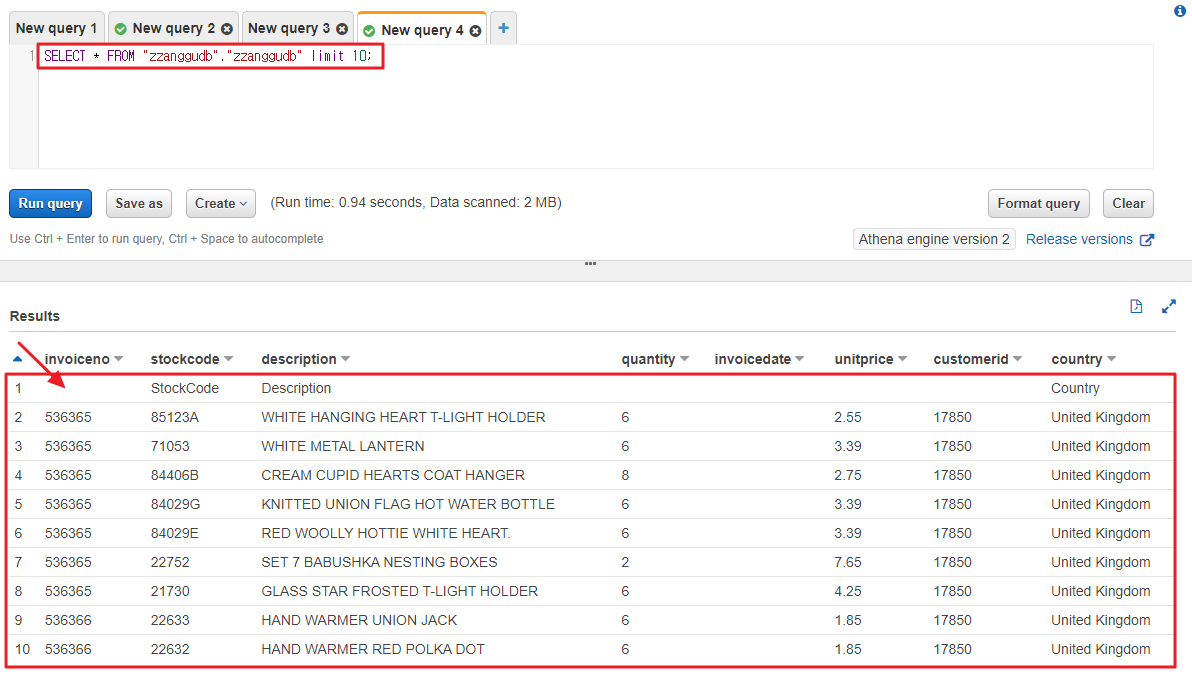
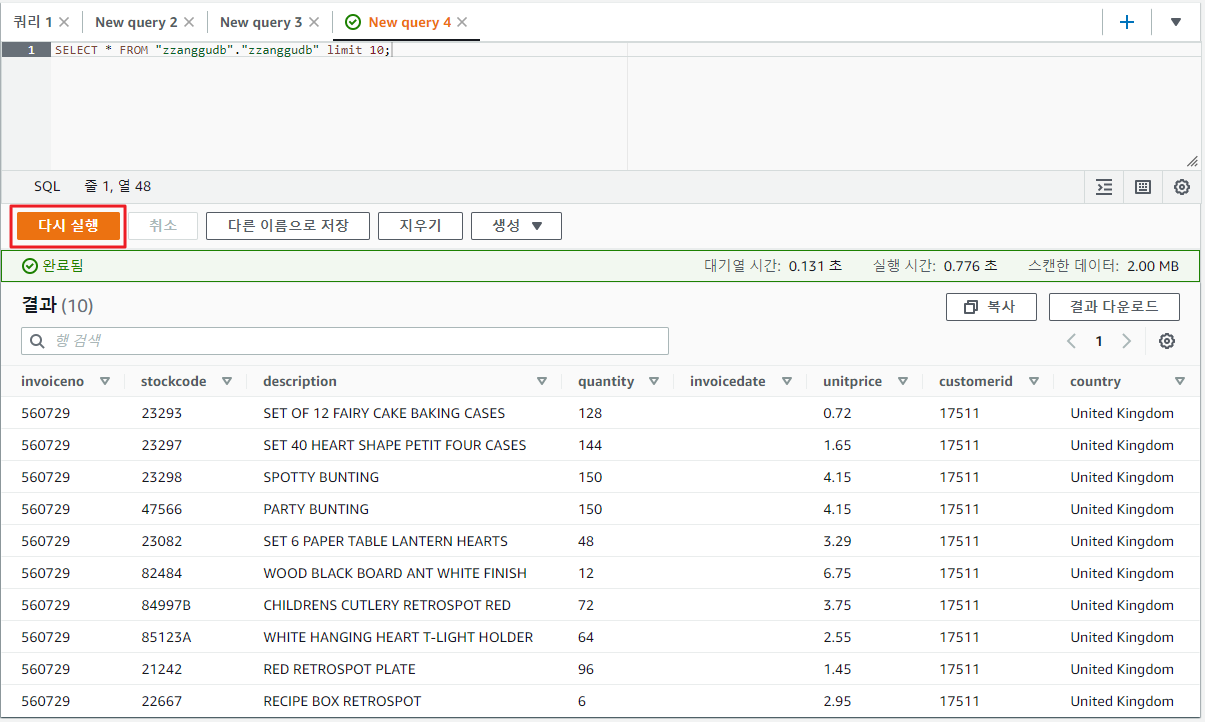
5. AWS Athena 쿼리 결과 확인하기
- AWS Athena의 쿼리 결과를 확인할 수 있다.
- 해당 쿼리를 실행하면 결과가 지정된 S3 저장소에 저장이 된다. 지정된 저장소를 확인하자.
- 아테나 쿼리결과 저장소 확인하기
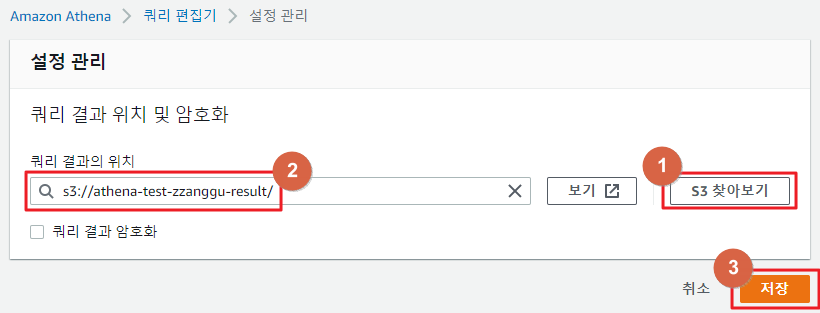
- 쿼리 편집기 → 설정 탭으로 이동하면 쿼리 결과 및 암호화 설정 화면이 나온다. 여기서 관리를 클릭하여 결괏값이 저장되는 저장소를 설정할 수 있다.

- 관리를 클릭하면 설정 관리 화면이 나오고 여기서 쿼리 결괏값을 저장하는 위치를 설정할 수 있다.
- 원하는 S3 저장소를 설정 후 저장을 클릭 하여 설정을 저장한다.
- 결과를 저장하는 S3 저장소는 원본 데이터가 있는 저장소는 피하는 것이 좋다. 원본 데이터가 저장되어 있는 S3 저장소 끝에 result 등의 문자를 추가로 입력하여 새로운 저장소에 결과 데이터를 쌓는 것이 좋다.
- 쿼리 결과 데이터가 정상적으로 저장 되었는지 확인하기
- 쿼리가 실행되고 결과값이 해당 S3 경로에 CSV 파일 형태로 저장되는 것을 볼 수 있다.
- 어쨌든 S3 데이터를 아테나에서 테이블로 생성하고 쿼리로 데이터를 조회 및 결과 데이터를 저장하는 작업까지 완료하였다.
- 생성된 테이블을 바탕으로 AWS 시각화 서비스인 QuickSight에서 결괏값을 시각화하는 작업을 수행할 필요가 있다. (추후 진행해보자...)
- 끝 -
'⭐ AWS > Athena' 카테고리의 다른 글
| Athena Case Statement (0) | 2023.07.20 |
|---|---|
| ALB Access 로그를 S3에 저장 후 Athena를 통한 분석 (0) | 2022.07.22 |
| Athena와 람다를 활용한 데이터 분석 (0) | 2022.01.18 |
| Athena 쿼리 예약 (0) | 2022.01.18 |
| AWS Athena에서 추가로 CSV 컬럼 추가하기 (0) | 2022.01.05 |


