반응형
# 학슴 내용
- 데이터 오브젝트 개념
- DataFrame
- Series
- 데이터 불러오기(read_csv)
Creating data(데이터 만들기)
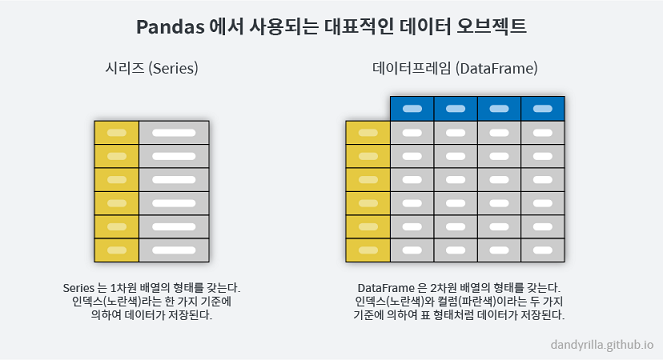
pandas는 DataFrame 와 Series 라는 중심 객체를 가지고 있으며 지금부터 무엇인지 살펴 보겠습니다.
DataFrame
DataFrame이란? 데이터를 나타낸 표입니다.
- 파이썬에서 데이터를 다루기 위해서 가상의 엑셀 시트를 만든다라고 이해해주세요.
- Pandas 는 Numpy를 기반으로 만들어진 데이터 제어(가공, 피보팅 등도 포함) 패키지로서, 순수하게 파이썬으로 데이터를 가공하려면 매우 힘든 일을 쉽게 처리해줍니다.
- Series 나 Dictionary 타입을 활용하여 만들 수 있다.
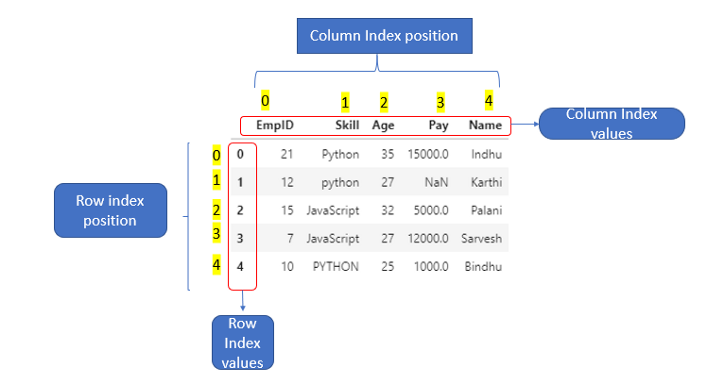
- 그림과 같이 엑셀 시트처럼 표 형식으로 데이터를 불러오고 데이터를 다루게 됩니다.
DataFrame 행렬은
- 개별 항목이 포함 되고
- 각 항목은 값을 가지며
- 각 항목은 행, 열에 표시 됩니다.
# 아래 코드를 실행하세요
import os
import pandas as pd
#세로로 값이 나열되는것을 확인 할 수있다.
pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})
# print(pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]}))
# 여기서 Bob과 Sue는 키가되고 리스트 값은 값이 됩니다.
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']})
# print(pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']}))
# 아래 코드를 실행하세요.
# 위의 코드와 다른점은 위의 코드는 앞의 인덱스가 0 ~ 1 ~ 2 로 시작된 반면 여기서는 ProductA, ProductB 등으로 표시 된다.
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])
print(pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B']))
# Series는 하나의 시퀀스로 구성된 데이터이다. 데이터 프레임은 여러 특성을 가지는 표 였다면
# 시리즈는 하나의 특성을 기반으로 표현하는 표로 생각하면 쉽다.
print(pd.Series([1, 2, 3, 4, 5]))
# Series란 데이터 프레임에서 하나의 열 입니다. 그래서 index를 Series에도 적용 할 수는 있지만
# Series의 name은 열의 이름을 의미하는 것이 아닌 전체의 이름을 나타 냅니다.
pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A')
print(pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A'))
# pandas의 핵심은 Series와 DataFrame인데, DataFrame이 더 큰 단위에 속하므로 DataFrame만 기억해도 무방하다.
# pd.read_csv() 함수는 CSV 파일로 저장된 데이터를 읽어오고 DataFrame으로 변환해주는 작업을 수행합니다.
# csv 파일을 불러오기
wine_reviews = pd.read_csv("./lib/input/wine-reviews/winemag-data-130k-v2.csv")
# shape를 사용하면 DataFrame이 어떻게 구성되어 있는지 확인이 가능 합니다.
wine_reviews.shape
# 실행을 하면 (129971, 14) 라는 값이 출력 됩니다. 이 값은 데이터가 13만개 정도로 구성 되어 있으며, 14개의 열로 이루어져 있다는 뜻입니다.
print(wine_reviews.shape)
# head()를 사용하여 처음 5개의 행을 불러와 보도록 하겠습니다.
print(wine_reviews.head())
# pd.read_csv() 함수는 CSV를 불러오는 간단한 함수 이지만 실상은 CSV를 불러오는데 30가지 이상의 옵션을 줄 수가 있습니다.
# 예를들면 인덱스가 있는지에 대해서 알아볼 수 있고, 인덱스에 대해 해당 열을 사용하도록 하려면 index_col을 사용하면 됩니다.
# 추가로 확인할 내용은 url을 참고 : https://pandas.pydata.org/pandas-docs/dev/index.html
wine_reviews = pd.read_csv("./lib/input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)
print(wine_reviews.head())참고
2022.02.08 - [파이썬/Pandas (데이터 가공 라이브러리)] - 파이썬 기본 파일 경로에서 내용 출력하기
파이썬 기본 파일 경로에서 내용 출력하기
# 파이썬 기본 파일경로를 확인하고 기본 파일경로에서 파일 내용을 출력하는 방법 1. 같은 레벨의 폴더 경로에 위치해 있어야 한다. - 아래의 캡쳐 이미지를 보면 /lib 폴더와 Pandas_data.py의 위치
may9noy.tistory.com
- 끝 -
반응형
'파이썬 > Pandas (데이터 가공 라이브러리)' 카테고리의 다른 글
| Pandas를 활용한 parquet → csv로 변환하기 (0) | 2023.01.05 |
|---|---|
| Pandas 데이터 요약과 맵핑 (0) | 2022.02.08 |
| Pandas 기초 및 활용 (0) | 2022.02.08 |
| 파이썬 기본 파일 경로에서 내용 출력하기 (0) | 2022.02.08 |
