챗봇 만들기 3탄 (특정 도메인을 학습시켜 보기)
# 나만의 LLM 만들기
나만의 LLM을 만들어보자.
1. 데이터 셋 만들기
일단 데이터가 필요하니까, 데이터는 검색문을 파라미터로 하여 구글에서 크롤링을 해오자.
아래와 같이 크롤링이 실행된다.

크롤링이 완료되면 일단 CSV 파일로 저장한다.
아래와 같이 저장이 된다.

2. 생성된 데이터 셋을 가지고 학습하기
데이터 셋 경로를 아래와 같이 크롤링 후 저장된 파일 경로와 파일로 지정한다.
해당 파일의 경로를 참고로 학습이 이루어진다.

학습을 시작하기 전에 새롭게 학습된 데이터는 아래와 같이 별도의 폴더로 생성되도록 구현했다.

학습을 시작
기본 모델에 크롤링한 데이터만 학습시키는 것이기 때문에 학습 시간은 사양 낮은 노트북을 에 비해 그리 오래 걸리진 않는다. 약 7분 소요.

3. 학습된 결과를 가지고 테스트
학습된 결과를 가지고 API로 테스트를 해보자.
학습이 완료되면 아래와 같이 폴더 별로 나눠서 저장된다. 간단하게 날짜와 시간 등으로 구분을 해놓았는데, 나중에는 바꿔야 할거 같다.

그리고 코드는 아래와 같이, 조금은 무식하게 분기하도록 되어 있다. 이건 나중에 파이프라인을 구현하면 어떨게 효율적으로 바꿀지 고민을 해봐야겠다.

그리고 출력 관련 파라미터들은 아래와 같다.
선택된 모델을 기반으로 답변을 만들어준다.

질문과 함께 API를 호출해 보자.
응답이 생각보다 늦다. API를 호출하고 보니 API를 호출할 때마다 CPU자원과 메모리 자원이 거의 100%까지 사용되는 것을 아래와 같이 볼 수 있다. 자원을 상당히 많이 잡아먹는 거 같다...
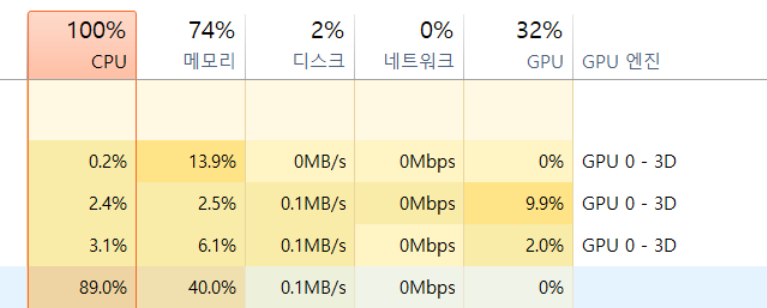
API를 호출한 결과는 아래와 같다. 상당히 적은 양의 데이터를 학습했지만 날씨와 관련된 답변은 매우 적은 양의 데이터를 학습한 것치곤 잘 대답해 주는 거 같다. 물론 정확도는 낮다. 근데 상당히 흥미롭긴 하다... 구글에서 크롤링한 소량의 데이터만을 학습했을 뿐인데, 날씨와 관련된 정보를 그럴듯하게 대답해 준다. (너무 느려서 2배속으로 봐야 됨.)
날씨 정보를 학습하지 않은 원본 모델에게 한번 동일한 질문을 던져보자.
비교를 하면 아래와 같다. (너무 느려서 2배속으로 봐야 됨.)
약간의 날씨정보만 크롤링하여 학습한 모델이 기본 모델보다 대부분 응답이 좋은 것을 볼 수 있다. (위가 학습된 모델, 밑이 기본모델)
그나저나 API 하나 호출하는데 CPU랑 메모리 리소스 엄청나게 잡아먹네...
오늘은 여기까지...
- 끝 -